Content-based Image Recognition (CBIR)
What was the project assignment?
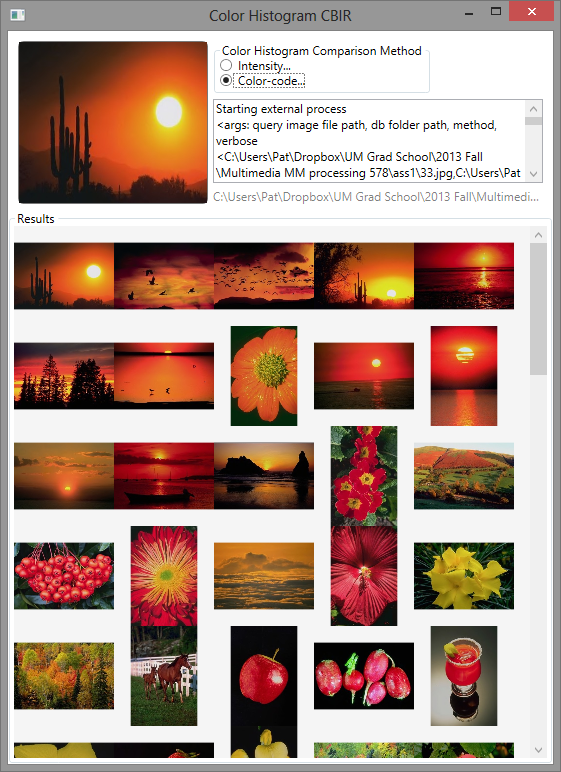
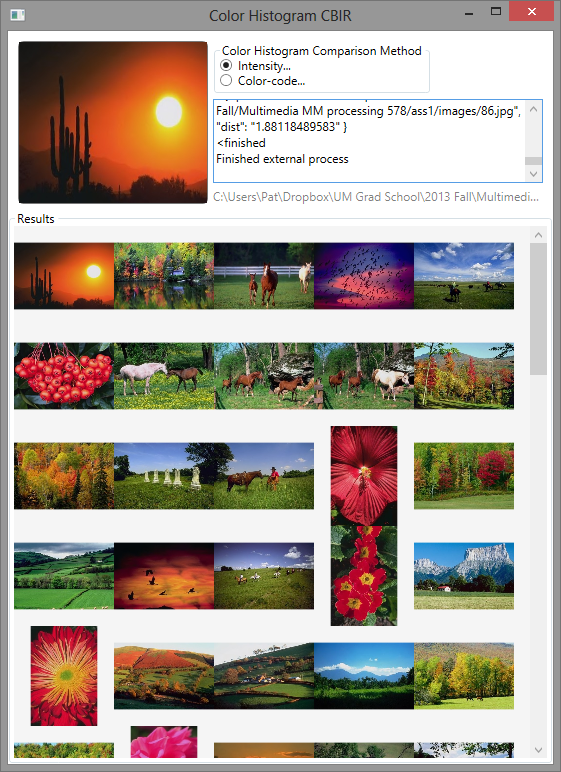
For two assignments in multimedia processing, CSCI 578, we were instructed to create a graphical content-based image retrieval (CBIR) system. CBIR is the idea of finding images similar to a query image without having to search using keywords to describe the images.
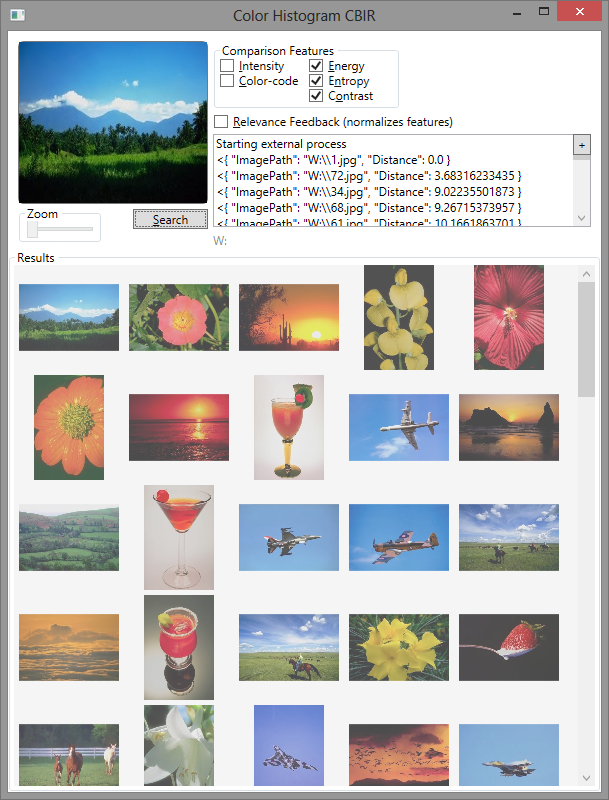
In part one, the image similarity features were either a histogram of intensity or a histogram of color code. Part two required implementation of a relevance feedback system (basically, a way to indicate which images were relevant and incorporate that information into subsequent searches). We also had to add three features indicative of the texture of the image: energy, entropy, and contrast.
I started with a front-end using Windows Presentation Framework (WPF) which called python code for the heavy lifting. Serialization of expensive objects was done with pickle, python’s default mechanism. All of the code was in one python script, and verifying intermediate output was not an easy task.
When given the opportunity to refactor the code for part two, I kept the model-view architecture the same (calling python code from WPF via stdin/out) but separated the model into modules. This enabled me to test and verify results on a single-file basis for every feature. I even created a commandline interface for relevance feedback. I also moved to using an sqlite database for caching image features. I thought about using the database for inter-process communication (rather than stdout), but I quickly abandoned that notion.
My reports for part 1 and part 2 are available for perusal.
What did you learn from the project?
I learned quite a few things, namely:
- Working with the commandline in windows is not as easy as it should be.
- Python, even with smart usage of numpy, is slow.
- WPF is powerful but unintuitive.
- CBIR is hard to do well. It would be even harder on a large corpus.
- Separating model and view, even to the extreme, is a good idea.
- Sqlite is great when you want a portable file and don’t want to run an entire DBMS service.
- Profiling python code can be really easy, or it can be extremely painful.
What are you most proud of?
Two things. First, I’m proud that I was able to profile my python code from part one and get results that allowed me about a 10x speedup. Second, I’m proud of how I was able to systematically modularize the code in part two to make testing significantly easier.
What would you do differently next time?
Instead of the sqlite module built into python, I’d use the dataset library to really simplify creation and maintenance of the cached features. Also, I would have loved to have live display of results, with animations to move the images into their correct order as they are analyzed. Originally, I had planned to allow more tinkering with the feature parameters (e.g. changing the intensity calculation by varying levels of RGB, adjusting the size and number of histogram bins, etc). If results could be calculated quickly enough, it would have been great to have live re-querying whenever the feature parameters changed - then it would have been a really useful tool for understanding each feature’s strengths and weaknesses in CBIR.